Backup practices could cost you
The risk of S3 replication and database dumps
September 18, 2023 | 18 min. readDan Eldad
VP of Data

VP of Data
Do you know the data risks of your regular backup practices? Have you thought of the potential security ramifications of manual database dumps or S3 replication? If not, and even if you have, this is the post for you.
I’ve previously discussed the risk of shadow data (those data stores you didn’t even know you had), and the team specifically dove into how versioning (a feature used to protect from accidental deletion) can unintentionally create shadow data.
There is another class of shadow data that’s caused intentionally by data backups. It seems counterintuitive since data backups are normally considered a data governance best practice. However, even the best of practices can have unintended consequences.
In this post I’ll give you the information you need to consider the dangers for two higher-risk backup practices in particular, manual database dumps and S3 replication, as well as suggestions on what you should consider to combat the risks of these practices. If these concepts are not familiar to you, consider first reading The Difference Between Backup and Replication. Overall automatic backups provided by the CSP’s are better than manual backups but even these should be used with great care. And with that, let’s dive into a quick overview of the types of backups.
Backing up a business’s files or databases is necessary because they ensure business continuity during an outage. Think JBS Foods or Royal Mail, both victims of ransomware groups who took their data hostage, halting operations until the issue was resolved. There are other uses for backups, which will be discussed as we get into the different types, but this is the core reason backups are critical for business operations: in case of data loss for any reason, be it ransomware, hardware or system failures, accidental deletion or natural disasters.
There are many ways to back up your cloud data, which can be categorized into three main types.
1. Manual backups, created at will by the user.
2. Automatic cloud platform backups, using tools from the CSP platforms, like AWS.
3. Backups created by third parties like CloudBerry Backup, NetBackup, and Rubrik.
There are risks inherent in the act of backing up data and creating an additional copy or copies of that data. Fortunately, I’ve got guidance for you on a couple of the more prominent backup practices, starting with manual database dumps and its potential dark side.
A manual backup is when a user creates a second backup copy of data by manually copying select files, folders, or databases. This type of backup requires a much more hands-on approach to data protection than automated systems. With today’s cloud systems, automated backups are generally preferred—indeed, I strongly recommend them (more on that below). But also acknowledge there may occasionally be times and places where one might desire a manual system, such as backups required at irregular times, for specific, granular data files, or for isolated environments.

There are a many different types of manual backups, but for the purposes of this article, I will note three relevant, common types:
1. Disk images: Disk images are a complete copy of a disk or volume used to restore the entire system or application. In cloud environments, disk images are typically stored as virtual machine images, and can later be restored in a different environment with all their data and settings.
2. File-level backups: File-level backups are copies of files one wants to back up. These can include day-to-day files like Excel spreadsheets or Word documents or system files and directories that contain critical data needed to restore a system or application. This differs from a disk image because you can pick and choose which files you want to back up as opposed to taking an image of the entire disk.
3. Database backups: The third category of backups are database backups. For this article, a database dump is a type of database backup. Both refer to a backup of a database, like Postgres or MSSQL (or many others), in which the data is saved in a file, typically in a way that can later be restored into a database of the same type. This type of backup or “dump” is usually made with tools included in the relevant database. For example Postgres provides a tool called “pg_dump” made exactly for this purpose.
Manual database dumps, also called “data dumps” or just “dumps,” can be a complete copy or a subset of the data, depending on the specific use case. As noted above, a dump saves the data from the database into a file or object in the cloud, typically in a way that can later be restored into a database of the same type.
There are several reasons for manual database dumps, including:
1. Backups – The core use case is to back up a database. This use case is no longer best practice, and I advise against using manual dumps in favor of automated methods.
2. Transferring data – Data dumps are an easy way to transfer data from a database to another location, say another cloud environment, and where it can be restored. Again, not something I advise doing manually given the sophistication of automatic cloud backups.
3. Testing and data manipulation – When an engineer wants to use the data in a database for tests or data manipulation/streaming, their queries can actually burden the database. This causes queries to execute more slowly, affecting product performance. In this case, the engineer may want to create a data dump to use for testing.
In general, dump files can be stored in a compressed format, such as `.tar`, `.gz`, or `.zip` in AWS, making them portable and easy to transfer between different systems and environments. They may also be encrypted or stored in a secure manner to protect sensitive data.
As with any shadow data, data dumps present several risks to organizations if not properly monitored and secured. These files can contain sensitive data; therefore, it’s important to ensure best practices are used when employing this technique. The major risks of manual database dumps include:
1. Vast and uncontrolled attack surface – When you create a database dump, you’re essentially making the possible attack surface twice as large. In addition to the actual database, you now have one or more copies of that data inside the database that reside in different places.
These dumps usually have much weaker defenses. While the original database requires login credentials and, sometimes, multi-factor authentication, the dump usually does not. This wide attack surface can lead to any number of problems, including a much greater chance of leaking sensitive data—whether by misconfiguration of access policies, attacker actions, or insider threat. When the data is available in more places, attackers have that many more chances to access it.
2. Privacy and compliance violations – Database dumps are one of the classic ways that data ends up in a non-compliant location and/or stored in a non-compliant way. Consider: You could have a database that stores GDPR-regulated data in the EU and is compliant with all relevant regulations. However, if an employee were to create a dump of that database and move it to a non-compliant location outside of the EU, it would be a regulatory violation. Even worse, the privacy team that makes sure the database itself is compliant would have no way of knowing this and would think that everything is up to code. That’s potentially a terrible, horrible, no good, very bad day.
3. Additional, unnecessary cloud costs – Last but not least, every time a database dump is created, you pay double to store that data. Not only are you paying to store the original database, but you are also paying to store the database dump. It’s easy to see how storage costs could quickly get out of hand, if there are no restrictions on when and how data dumps are used. Which is, of course, why I recommend organizational policies to keep track of dumps. More on that below.
Example:
An engineer creates a database dump for tests she is running for a project. As time goes on, she moves on to other projects and forgets about this dump. The cloud provider, however, does not forget about the storage required to maintain this dump, and so the dump continues to generate costs and additional risk week over week, month over month, year over year.

As a best practice, I recommend avoiding manual dumps unless absolutely necessary because there are fewer guardrails to this type of custom, ad-hoc backup. Instead, rely on automated backups through your cloud platform wherever possible since these are managed in the cloud platform and are much easier to keep track of.
If you do need to employ manual dumps, here are some best practices:
1. Any dump used for ad-hoc purposes, like transferring data to a different account or testing, should be deleted immediately after use.
2. When systematically using database dumps (say taking a database dump every 7 days), make sure you set up a lifecycle policy so these dumps are deleted after the appropriate amount of time.
3. Limit the number of people who can create a manual database dump to the bare minimum, and make sure they are acutely aware of the risks.
4. Think about some organizational policies that can help you keep track of database dumps. For example, set up a specific place where all these dumps should be stored, to minimize the risk of shadow data.
With that, I’ve given you the reasons you may want to do database dumps, the risks they present, as well as my opinions on how best to mitigate that risk. Now, let’s consider automated backups done through your cloud platform.
All cloud providers offer automated options for backing up the valuable data stored in the cloud. These automated backups alleviate the burden of manual backups and ensure the organization can easily restore their data to avoid or minimize business interruptions. For more on this, read Data Backup Automation and Why It Matters. Automated backups may also add a measure of improved security, although cautious use is still required.
Because AWS is the prevalent platform, and we’ve already unpacked the shadow data risk of versioning, this article will dive deeper into Amazon S3’s replication service, a type of automatic cloud platform backup for this specific service. Let’s discuss why you might choose to replicate, the risks that this backup method presents, and how to mitigate those risks.
As defined by AWS, “Replication enables automatic, asynchronous copying of objects across Amazon S3 buckets.” There are many reasons to replicate objects across buckets, including protecting data, complying with regulatory requirements, increasing efficiency, and reducing costs. However, as with database dumps, there are risks inherent with replication and pitfalls to be aware of.
Note: For replication, every item within a bucket, be it a file or the metadata describing that file, is an object. Every object in a bucket is a file and the two words can be used interchangeably.
There are different types of replication, to meet different needs. Replication to a single destination bucket or multiple destination buckets, replication to different AWS regions or the same region, live or batch—just to name a few. I won’t burden you with the full list, but do want to highlight:
Live Replication automatically replicates new objects as they are written to the buckets.
1. S3 Cross-Region Replication (CRR)
a. As stated by AWS, “CRR allows you to copy objects across Amazon S3 buckets in different AWS Regions.” This type of replication is best suited to meet the needs of those with regulations requiring data be stored at a greater geographic distance than is standard, for operational efficiency in data analysis, and/or to minimize latency for users by putting data geographically closer.
2. S3 Same-Region Replication (SRR)
a. As stated by AWS, “SRR is used to copy objects across Amazon S3 buckets in the same AWS Region.” This type is used to comply with data sovereignty laws, to simplify the processing of logs by aggregating them, and/or when you want the same data in your production and test accounts.
Batch Replication offers an on-demand way to replicate objects to different buckets, and can be run as needed, not automatically.
Note: Versioning must be enabled in order to replicate data, for both your source and your destination buckets. If you’d like more on versioning, read our post “Versioning in Cloud Environments: How It Can Cause Shadow Data & How to Mitigate the Risk.”
Once you’ve determined the type of replication, enabled versioning, and replicated data into a secondary bucket, what happens when you delete that source data?
From a data security standpoint, this is a key area of replication to be aware of. The default for S3 Replication is that if you are using the latest version of the replication configuration, the delete marker is only added in the source bucket. It does not carry over to the replicated objects. This is intended to protect data from malicious deletions, one of the reasons for backup in the first place. But it means that if you want to avoid having the shadow, duplicate copy in the replicated bucket, you must do more.
To delete the source file and the replicated object, you must enable delete marker replication. These markers are then copied through to the destination buckets, and S3 behaves as if the object is deleted in both source and destination buckets. Delete marker replication can be applied to either the entire bucket or select objects within the bucket that have a specific prefix.

Caption: Screenshot sample of delete markers from the AWS documentation
Taken together this means it’s very easy to generate shadow copies of replicated objects, even if one meant to delete them along with the source object.
While there are many reasons one might want to replicate an S3 bucket or certain objects within that bucket, doing so presents certain risks.
The risks are:
If the replication configuration is set for the entire bucket/prefixes in the bucket, this could mean that all new objects created in the source bucket are then also transferred to a different bucket. This could lead to privacy or compliance violations in a number of different possible ways:
1. Violation of data residency requirements: If the replication is in a different region, even if initially there was no regulated data (such as data governed by GDPR) in the bucket that’s being replicated, somebody that is not aware of the replication can easily put data in a bucket that is in Europe without being aware that data is then being replicated to a bucket in the US. This may then trigger a data residency violation, depending on the rules, the data and the geographies.
2. Retention violations: If data can only be kept for a certain amount of time, and is deleted after that time from the original bucket but is not deleted from the replicated bucket (and is thus kept indefinitely) that’s a huge problem.
3. Data access/erasure requests: Almost all data privacy and compliance laws have clauses stating that a user can request access to all his data. If the privacy team doesn’t know that the user has data in the replicated bucket they won’t give that to him. Same goes for data erasure requests: if the privacy team doesn’t know about the replicated bucket, they will delete data from the original bucket but still have data on that user in the replicated bucket, which is a violation.
All replicated data is potentially unknown and unmanaged shadow data. This risk becomes acute when files are deleted only from the source buckets, but left forgotten in the replicated bucket.
Often, developers and data scientists are replicating buckets without the knowledge of security, and sensitive data could be replicated in a different bucket entirely unknown to the team that needs to secure it. And no one wants customer files or trade secrets out there in an unknown, unmanaged replicated object—just waiting to be accessed.
Destination backup buckets can have different permissions than the source bucket. And access to those backup buckets may be public or given to third parties, which could lead to the inadvertent exposure of sensitive data.
Imagine the following scenario: you have a bucket containing non-sensitive data. You replicate this bucket and set the destination bucket to have public access so anybody can access this non-sensitive data. You don’t have to change permissions for the source bucket which is in a more sensitive account.
Time goes on, and you forget this bucket is being replicated. Now you put sensitive data in the source bucket. You check the permissions of the bucket to ensure they’re appropriately non-permissive. However, this data is being replicated into a different bucket with public permissions, meaning that sensitive data is now exposed. If all permissions were exactly the same in replicated buckets, then checking the permissions of the source bucket would be enough to ensure that you can put sensitive data in there, but that’s not the case.
AWS charges based on usage, meaning you pay twice for replicated data. Once for the source file. Once for the replicated file. This duplicate cost is incurred both for the files you know you have replicated and, unless the right steps to delete replicated objects as well as the source files are employed, also for those files you believe you’ve deleted. Which means that you may well be paying for storage of data copies you don’t need.
Note: Interestingly, we see very low percentages of replicated buckets in our data. This might be because replication is a feature that is still not widely used (even given the many reasons for its use). When prioritizing which data to find and secure, consider this a lower priority because it’s far less likely to happen. But don’t ignore it. All it takes is one sensitive data file that is replicated, deleted in the source bucket, but not the replicated bucket, then found by an adversary to ruin one’s day, week, or even year. Remember: knowledge IS power.
The first way to combat the risk of replicated data is to understand if data is being replicated. You can run the following command in the AWS CLI:
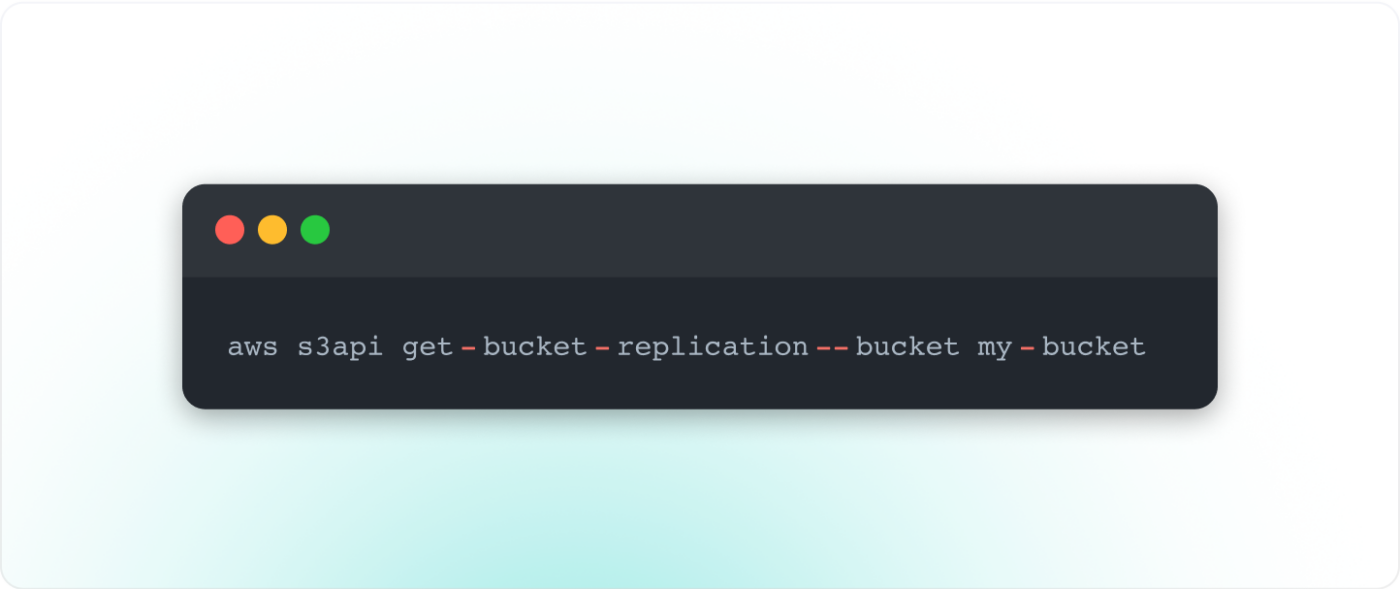
Please note that you would need to run this bucket by bucket in your environment. For more information regarding this command and the output received, see the AWS documentation here.
In general, I recommend it is best to use replication very sporadically and for well thought out purposes when other automated solutions don’t work. While it is a powerful tool, it comes with significant potential risks. You don’t want to get to a situation where many buckets in your environment are being replicated and it becomes impossible to keep track. When thinking about whether or not to replicate, the guideline is to only use it when you must, and then only after you’ve thought it through very very well.
The third and final backup type is those created by third parties like CloudBerry Backup, NetBackup, and Rubrik. There are also Disaster Recovery-as-a-Service (DRaaS) solutions. While there is much that could be said on third-party backups, for this post I don’t want to dive in on weighting the data risks against the rewards because, frankly, third party backups are usually safer than the other practices mentioned here.
After all, there is a responsible third party in charge of making sure the data is secure, and data from third party backups is often much harder to discover and classify. If you’re looking at backup via a third party, do your due diligence when selecting a vendor. Look for one that follows solid security practices, such as encrypting data, having a framework for where they save data, and maintaining relevant certifications like SOC 2, for example.
In this post I’ve offered some helpful data points to help in making the risk and reward calculation on the operational practices of backups, more specifically database dumps and replication. There may be reasons you choose to employ manual backups, and there may be reasons to consider S3 replication, and now, I hope you have a much clearer picture of the data risks you’re exposing your organization to with each.
To catch up on our earlier research, check out our post on publicly exposed S3 buckets, or our post on versioning.
Get notified when a new piece is out

