Why data discovery and data classification are so difficult for organizations – and how to make it easier
October 17, 2023 | 11 min. readOrin Israely
Product Manager

Dave Stuart
Sr. Director of Product Marketing
Product Manager
Sr. Director of Product Marketing
Mapping, classifying, and reporting on data in the cloud is challenging for many companies, and the more cloud-centric the company, the greater the challenge. Businesses with a “cloud first” operating mode simply experience a faster rate of change. Their environments are complex – comprising multi-cloud, SaaS, and on-premise elements. They are dealing with massive amounts of data and are subject to new and changing regulations.
The result is a vast and complex ecosystem with disparate data stores that often do not have clear organizational owners. Instead, we see CIOs, CISOs, and CPOs sharing this responsibility. Under these circumstances, it’s easy to see how blind spots and nearly unchecked data proliferation can occur. And unfortunately, you can’t protect or manage data you don’t know exists.
Automated discovery and classification processes and tools must be put in place to ensure end-to-end visibility into your dynamic cloud ecosystem. An autonomous classification engine helps provide continual security posture awareness of your sensitive data and accurately guide data security, governance, and compliance efforts.
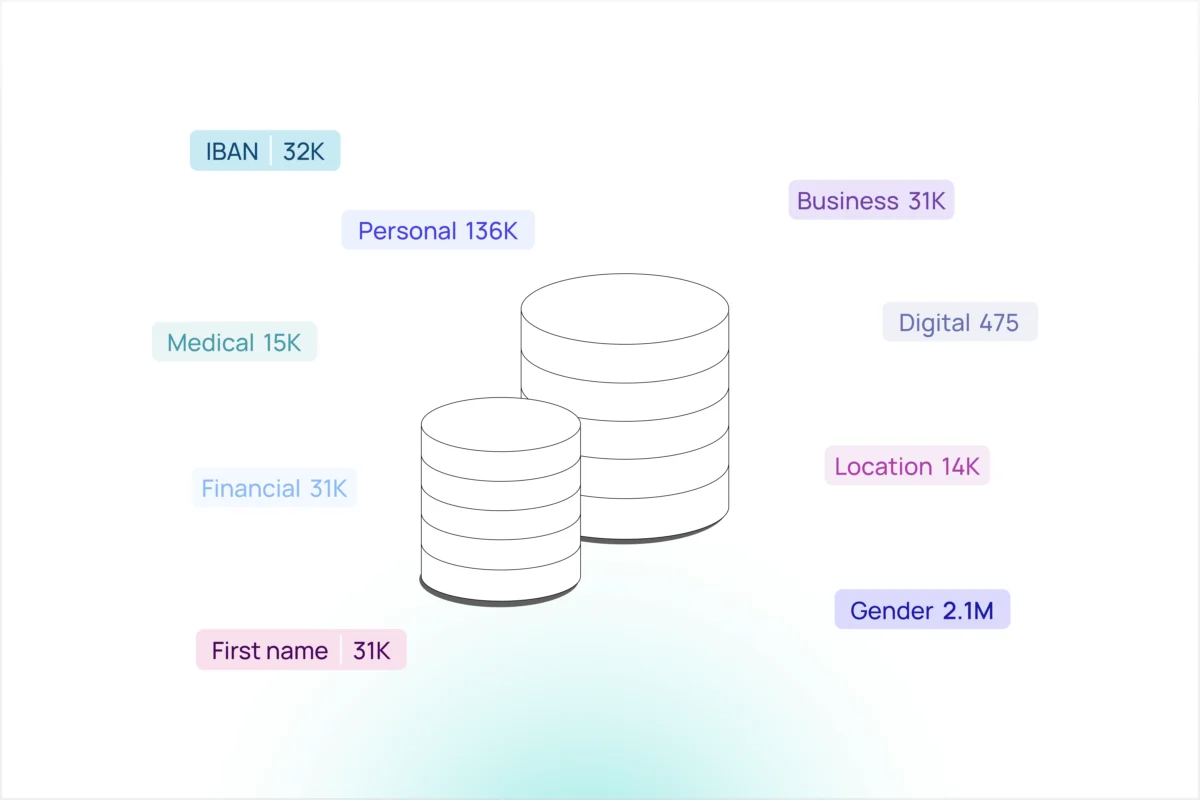
Data discovery and classification tools are used to achieve a comprehensive view of all data created and utilized by an organization, providing granular visibility into the data type and sensitivity, risk levels, security posture, and more. This process is split into two distinct functions: data discovery and data classification.
Data discovery: Understanding where you have data in your environment across all public clouds, data warehouses, SaaS applications, cloud file shares, and on-prem storage. You must find all of your data before you can secure it. Discovery can also provide useful context such as the data’s owner, who has access to it, who is using it.
Data classification: Sometimes referred to as “tagging” or “labeling” the data, this process helps you determine what data you have and its sensitivity. To improve accuracy and eliminate false positives, intelligent validation methods may be employed to confirm classification.
Between these two processes, you’ll have most of what you need to assess risks and make informed decisions, including:

Knowing the context is important since not all data needs the same protections. Your policies, guardrails, and priorities in terms of your security and governance effort will be different depending on context. For example, if you search your infrastructure for email addresses, you may find every instance of an email address, but is that level of information actionable?
To measure the risk level associated with these emails, you must know if they belong to employees, vendors, or customers. You should also consider what other PII or sensitive data those emails are stored with, such as first and last names or social security numbers. You will want to know where they reside for residency compliance as well.
This context completes the picture, ensuring you fully understand your data’s sensitivity so that you can assess the risks and apply the appropriate security posture.
Data discovery and classification are foundational steps for these business-critical initiatives:
The insights generated through data discovery and classification help you to establish appropriate policies and controls that can vary greatly depending on industry and application. Hence, agility and flexibility to customize also become important solution characteristics.
Gaining visibility into your cloud data landscape is not a simple or easy process for most. As previously mentioned, the complexities of modern, multi-cloud environments and the rapid proliferation of data exacerbate the related tasks. Under these conditions, shadow data, or lost or forgotten data, becomes a significant concern. In fact, 68% of security professionals say shadow data is their biggest challenge.
The problem is aggravated by the use of legacy processes or solutions, which can’t meet the needs of today’s cloud data security. The challenges with current approaches include:
None of the above approaches can provide the necessary visibility to locate shadow data and fully address your cloud security posture.
A powerful cloud-native data discovery and classification engine is foundational to all cloud data security, governance, and privacy efforts. It enables full, continual visibility to match the dynamic nature of the cloud.
It’s not feasible (or cost-effective) to monitor all data at all times. Instead, the information gathered through data discovery and classification enables you to prioritize data with the highest risk level. It also allows you to quantify the impact of potential risks to better direct hardening or remediation efforts. Knowing where your sensitive data is at all times, enforcing good posture, and monitoring for threats can help minimize breach impact and thwart data exfiltration.
Adhering to regulatory controls and standards frameworks for data privacy is very demanding in the dynamic world of multicloud. Automating the discovery and classification tasks allows focus to remain on the application and tuning of compliance policies, and frees security teams for proactive investigation and timely responses to exceptions or violations. It allows organizations to avoid hefty fines or penalties for non-compliance, as well as demonstrate best practices to all stakeholders.
Shadow data often contains redundant, obsolete, and trivial (ROT) data, like a backup of an application no longer used by the company. Data discovery and classification will identify ROT data, allowing you to remove it, minimize risk, and reduce the amount and cost of cloud data storage.
Data discovery and classification are the foundation for critical data security and governance functions, such as:
With so much data moving to and through the cloud, we’ve reached a point where data discovery and classification are no longer a “nice to have” but rather a “must have.” They are the foundation upon which all other security, governance, and privacy initiatives should be built. By implementing cloud-native solutions and automating your discovery and classification processes, you can free up your team to focus on maintaining your cloud data security posture.
You shouldn’t stop with a simple data cataloging tool. The map of your cloud data landscape is vital for all security, governance, and privacy efforts, but these functions are stronger when they’re integrated together. Choose a data security platform that supports end-to-end identification, protection, detection, and response capabilities, designed for multi-cloud and SaaS applications.
Laminar’s agile data security platform for multi-cloud features a powerful, cloud-native discovery and classification engine, ensuring you have visibility into all data assets stored within your ecosystem. Laminar’s easy-to-digest dashboard displays these insights, with both granular and high-level details, to inform important security, governance, and privacy functions.
These are the capabilities your data discovery and classification system must have.
| Autonomous and continuous scanning | Your solution should be able to scan every part of the IT infrastructure, including all cloud platforms, applications, and on-prem data stores. These scans should be autonomous, not requiring login credentials, manual connection, or direction. They should also be continuous to keep up with fast-paced cloud data access and usage, allowing you to catch policy violations quickly. | |
|---|---|---|
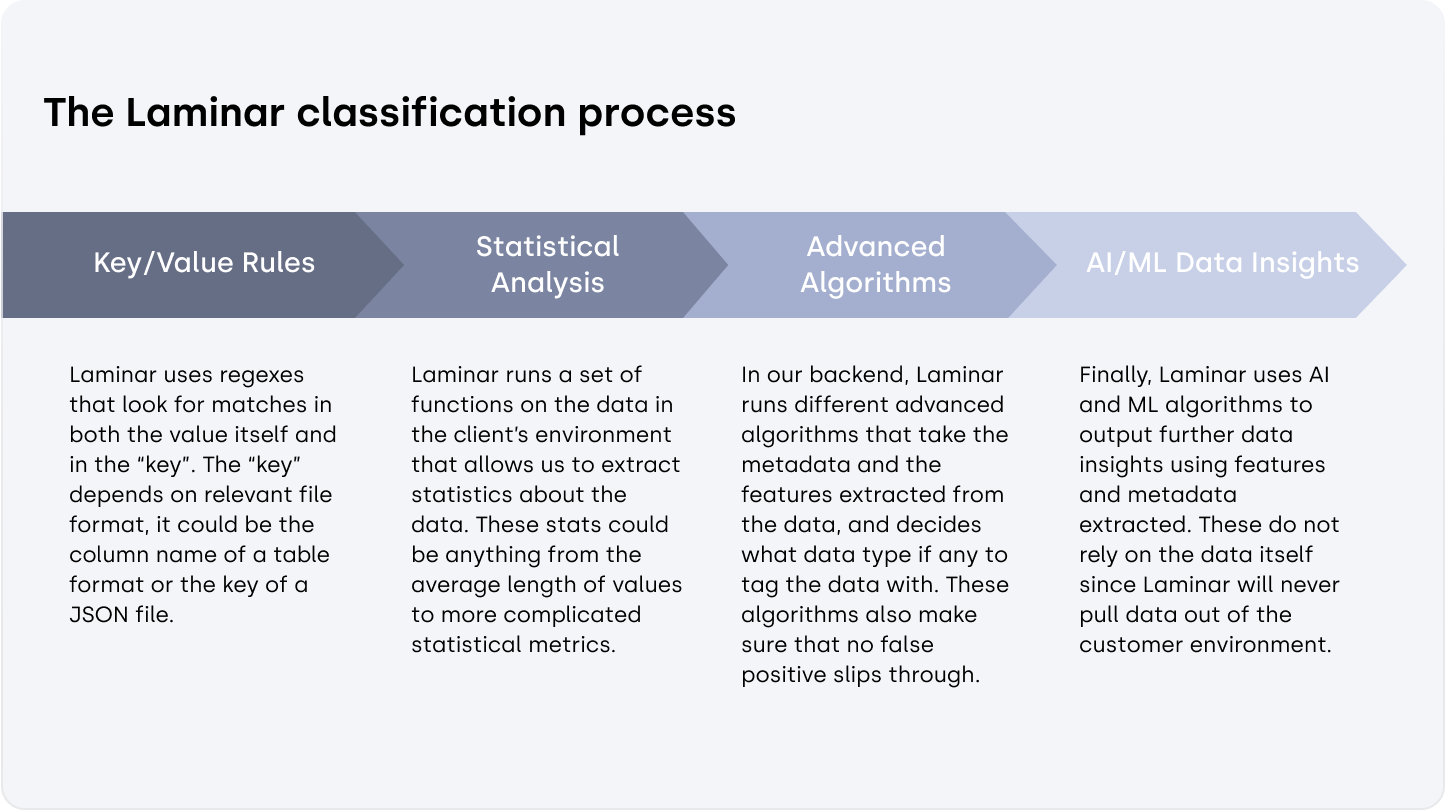
| Provide meaningful and accurate context | Context is vital for determining the risk level associated with a data set and accurately flagging violations. Your data discovery and classification engine must be able to ingest the whole contents of a file, see what else is stored near it, the name of the file, all the way down to the column name.
It’s also important that your discovery and classification solution can validate the information it gathers. For example, you want to know if the alert actually flagged an unsecured credit card number or if it simply picked up on a number with sixteen digits. AI and ML features can learn from the validation process and reduce false positives, which can erode trust and waste valuable resources. |
|
| Multi-layered sensitivity levels or categories | Classification capabilities should have enough depth to provide actionable insight. Ideally, your solution will offer out-of-the-box classifications and the ability to customize classifications to fit your unique business needs. At the least, your classifications should include data type, ownership, location, sensitivity, usage and file type. | |
| Achieve the above without increasing data risk | Your data discovery and classification platform should fulfill all of these functions without creating any additional risk. That means it shouldn’t move, duplicate, or store any data outside of your environment. | |
| Apply AI intelligently | Laminar employs AI smartly to optimize classification accuracy while keeping data secure in the customer environment and performing scanning cost-effectively. The main goal is to have accurate data classification. We use AI where it helps that goal, but we do not over-hype the use of AI or apply it unnecessarily in areas where it is ineffective or inefficient to do so. | |
| Unified console with a modern, easy-to-use interface | The data discovery and classification process is intended to increase visibility and provide actionable insights. Neither of those are helpful if they aren’t presented in a clear and consumable manner. Your solution’s dashboard should tell you at a glance what your highest-risk asset and data exposures are or policy violations and remediation suggestions. | |
| API integrations with other security stack components | Whether you’ve implemented SIEM, SOAR, or ITSM, your data discovery and classification must be able to integrate with them to streamline analysis and remediation workflows. Your tool should be able to share sensitivity classifications and related discovery context with other infrastructure or vulnerability solutions to improve their ‘actionability’ and remediation prioritization for misconfiguration vulnerabilities. | |
| Flexibility to scale up quickly | To keep pace with the explosion of data in the cloud, your data discovery and classification platform should be able to scale up without breaking or slowing internal processes and systems. Automation plays a big role, as does asynchronous or non-intrusive scanning capabilities. | |
Get notified when a new piece is out

